
1.5. Konfiguration
2 Übungen · ca. 27 Minuten
Umfangreiche Konfigurationsmöglichkeiten
Bevor Du Deinen ersten Crawl startest, solltest Du Dich einmal mit den Konfigurationsmöglichkeiten des Programms vertraut machen. Dazu kannst Du im Hauptmenü unterhalb des Menüpunkts Konfiguration eine Reihe von Optionen sehen.
In dieser Lektion lernst Du wichtige Einstellungen für Deinen Crawl kennen. Viele davon verbergen sich unterhalb von Konfiguration > SEO Spider.
SEO Spider-Konfiguration
Das Herzstück des Konfigurationsbereichs besteht aus mehreren Tabs.
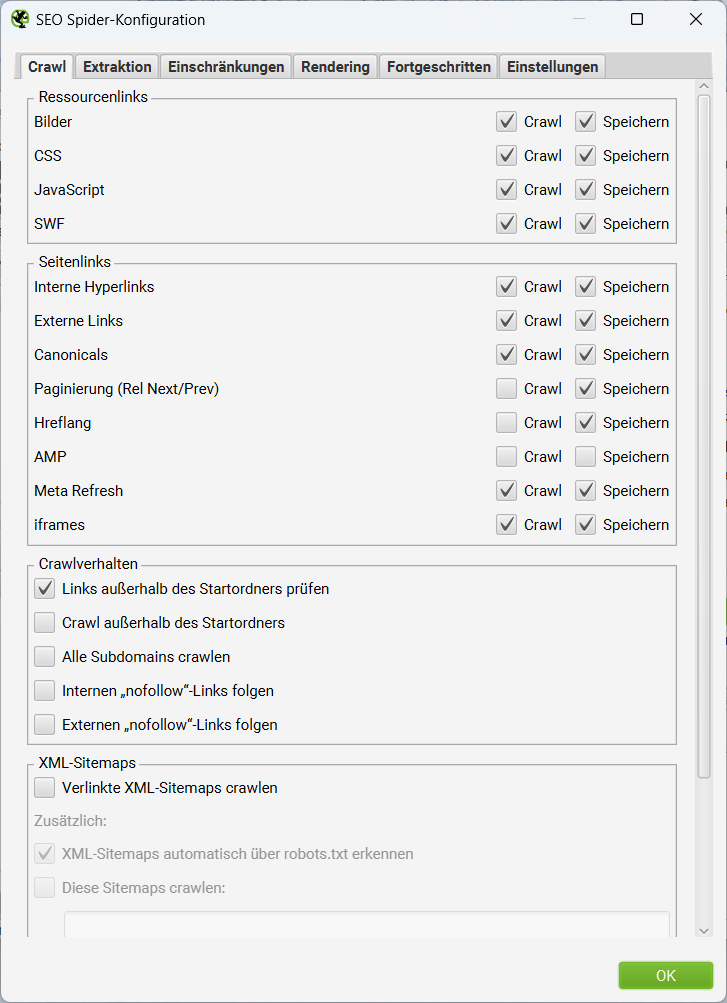
SEO Spider > Crawl
Der erste Tab Crawl fragt ab, ob bestimmte Dateitypen oder Links berücksichtigt werden sollen. Dabei kannst Du per Checkbox zwei unterschiedliche Optionen wählen:
- Crawl
Sollen Elemente dieses Typs gecrawlt und die Antworten des Webservers (Statuscodes) dazu erfasst werden?
- Speichern
Sollen Elemente dieses Typs während des Crawls gespeichert werden und danach innerhalb des SEO Spiders zur Verfügung stehen?
Nicht alle Optionen sind hier von Beginn an aktiviert. Im Standard-Fall ignoriert der SEO Spider beispielsweise AMP (kein Crawl, kein Speichern), folgt keinen Paginierungen per Rel Next/Prev und crawlt nur die aktuelle Subdomain der eingegebenen Start-URL.
SEO Spider > Extraktion
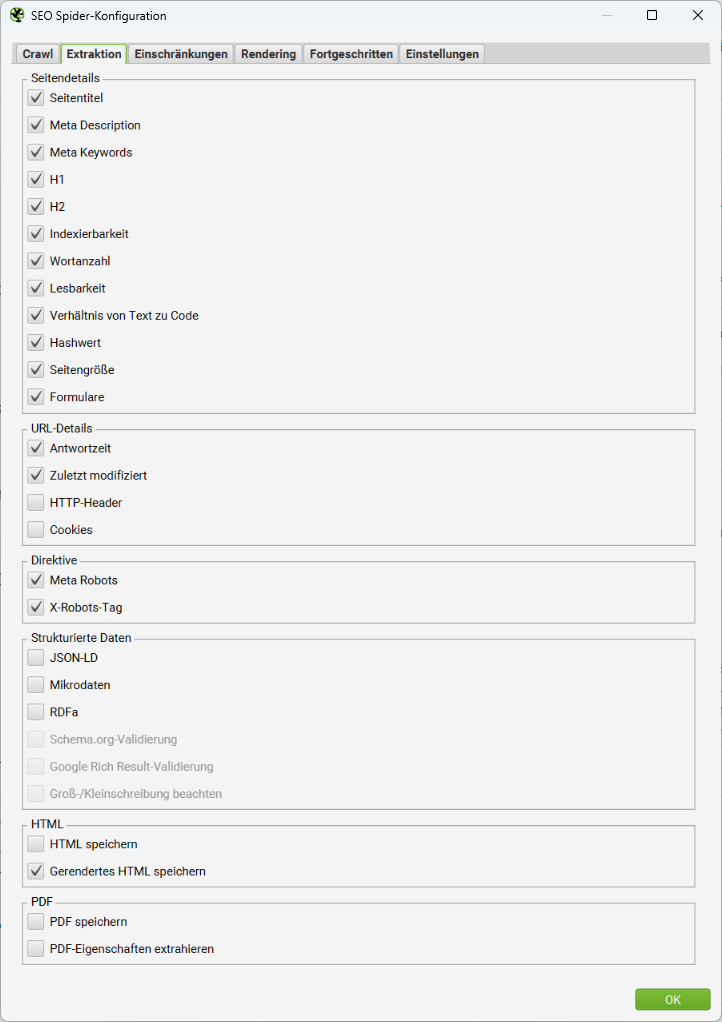
In diesem Tab werden Details für die Datenerfassung vorgegeben. Du legst hier also fest, welche Details einer Website-Adresse gespeichert werden sollen, wenn sie vom Spider gecrawlt wird. Auch hier sind zum Start nicht alle Optionen vorausgewählt. Standardverhalten des SEO Spiders ist es beispielsweise, dass Informationen zu strukturierten Daten nicht erfasst und validiert werden.
Weiter unten in dieser Optionenliste findest Du den Abschnitt HTML. Hier kannst Du wählen, ob für jedes gecrawlte HTML-Dokument auch der Quellcode gespeichert (und damit später auch durchsuchbar gemacht) werden soll. Es wird dabei zwischen zwei Formen des Quellcodes unterschieden: Vor und nach der Ausführung von JavaScript.
HTML speichern bezieht sich auf das vom Webserver ausgelieferte HTML, also die Rohfassung. Das ist übrigens auch die Version, die Dir Dein Webbrowser anzeigt, wenn Du dort die Quellcode-Ansicht auswählst.
Gerendertes HTML speichern lässt Dich das möglicherweise durch JavaScript veränderte, gerenderte HTML eines Dokuments abspeichern. Mitunter kann es wertvoll sein, die Unterschiede zwischen der Rohfassung und der gerenderten Version zu betrachten, um Fehler zu finden.
Wichtig: Gerendertes HTML kann der SEO Spider nur dann speichern, wenn in den Rendering-Optionen auch die Ausführung von JavaScript aktiviert wurde.
Selbst wenn im Abschnitt zu PDF-Dateien kein Wert ausgewählt ist, werden bei einem Crawl der Titel und die zugehören Keywords aus den Meta-Angaben einer PDF-Datei erfasst. Sollen zusätzlich die PDF-Eigenschaften aus einer Seite extrahiert werden, kommen weitere Werte dazu: Erstelldatum, Änderungsdatum, Autor, Thema, Anzahl Wörter und Anzahl Seiten.
SEO Spider > Einschränkungen
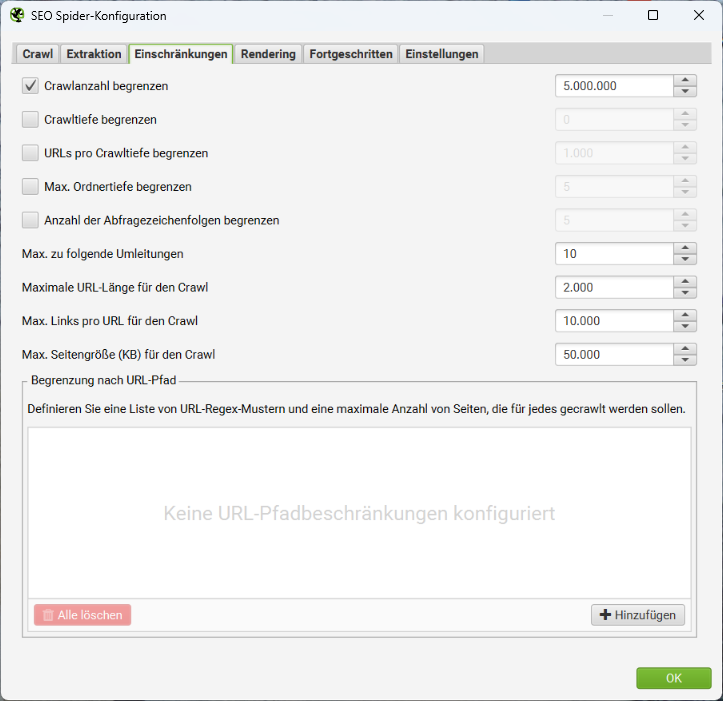
In der kostenfreien Version des Screaming Frog SEO Spiders ist die Anzahl von URLs in einem Crawl begrenzt. Mit der kostenpflichtigen Vollversion entfällt diese Limitierung. Der zum Start vorgegebene Wert von 5 Millionen URLs kann dann auch durch eine beliebig höhere Zahl ersetzt werden. Du solltest aber in Erinnerung behalten, dass irgendwann Dein Computer in Hinblick auf Festplattenplatz und Arbeitsspeicher an seine Grenzen kommen wird.
In den nachfolgenden Optionen kannst Du Angaben zur Crawltiefe und Ordnertiefe justieren. Eine Crawltiefe von 1 gibt an, das der Spider allen Links folgt, die direkt von der Start-URL weiterführen. Eine Crawltiefe von 2 gibt an, dass der Spider auch den Links dieser Unterseiten noch folgt. Standardmäßig sind keine Limitierungen der Crawltiefe vorgesehen. Es werden alle erreichbaren Links der gleichen Domäne ausgehend von der Start-URL gecrawlt.
SEO Spider > Rendering
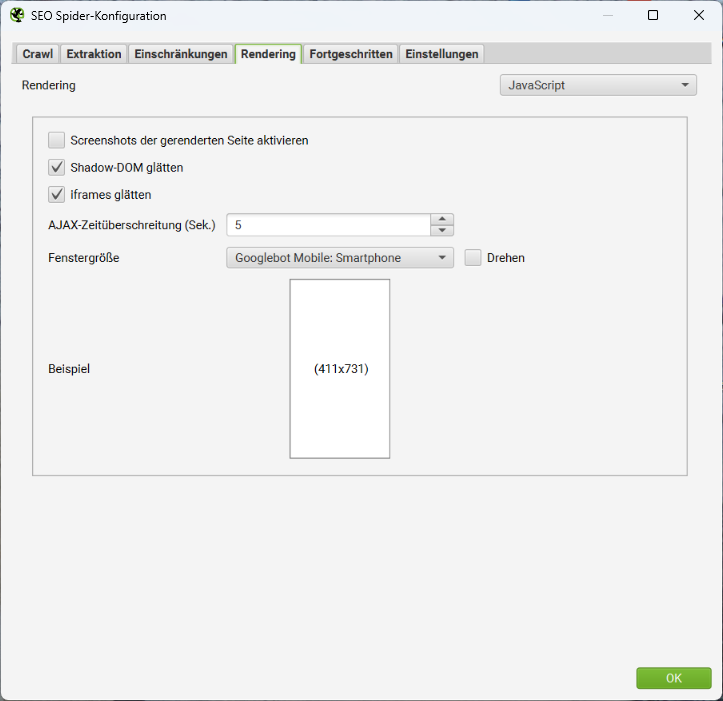
In diesem Abschnitt legst Du den Rendering-Modus für Deine Crawls fest.
- Nur Text
Der SEO Spider crawlt und extrahiert nur das ursprüngliche HTML. AJAX-Crawl-Schema und clientseitiges JavaScript werden ignoriert. - Altes AJAX-Crawl-Schema
Der SEO Spider folgt – wenn vorhanden – dem inzwischen veraltete AJAX-Crawl-Schema von Google. Anderenfalls wird das ursprüngliche HTML wie im Standardmodus Nur Text gecrawlt. - JavaScript
Der SEO Spider führt clientseitiges JavaScript aus, indem er die URLs in seinem integrierten Chromium-Browser rendert und das gerenderte HTML nach Inhalten und Links durchsucht und die Daten extrahiert.
Wenn Du das JavaScript-Rendering auswählst, ist standardmäßig aktiviert, dass Screenshots von gerenderten Seiten erstellt werden. Du kannst dafür verschiedene Fenstergrößen wählen. Beispielsweise die typischen Abmessungen der Googlebots für Desktop oder Smartphone.
Google fügt iframes in ein div im gerenderten HTML einer übergeordneten Seite ein, wenn das serverseitig nicht unterbunden wird. Voraussetzung dafür ist, dass die Höhe festgelegt ist, ein mobiler Viewport vorhanden ist und die Seite nicht mit einem noindex-Parameter ausgeliefert wird. Wenn Du iframes glätten wählst, wird der SEO Spider versuchen, dieses Verhalten von Google nachzuahmen.
Die AJAX-Zeitüberschreitung ist die Zeitspanne in Sekunden, die der SEO Spider für die Ausführung von JavaScript benötigt, bevor er eine Seite als geladen betrachtet. Der Timer startet, nachdem der Chromium-Browser die Webseite und alle referenzierten Ressourcen, wie JS, CSS und Bilder, geladen hat.
Wichtig: Google behandelt das Thema Zeitüberschreitungen tatsächlich deutlich flexibler als die voreingestellte 5-Sekunden-Marke. Unter anderem werden auch die Netzwerkaktivität und das Caching in den Maximalwert einberechnet. Aber auch Google hat nicht unendlich Geduld. Inhalte, die gecrawlt und indiziert werden sollen, müssen daher schnellstmöglich verfügbar sein. Anderenfalls bleiben sie für die Suchmaschine unsichtbar. Das 5-Sekunden-Limit ist somit kein feststehender Grenzwert, sondern eine gute Faustregel, um für Nutzer und Suchmaschinen bestmöglich zu funktionieren.
SEO Spider > Fortgeschritten
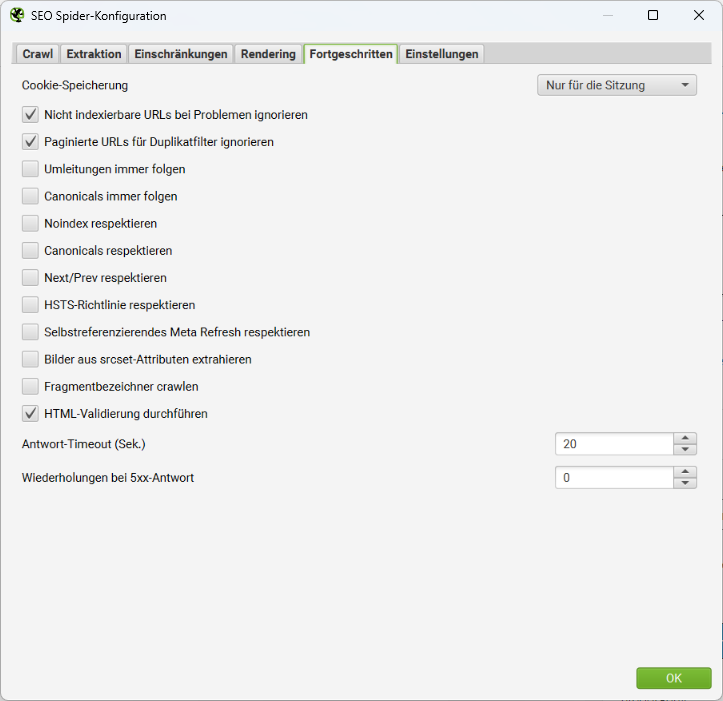
Eine Einstellung in diesem Tab solltest Du Dir besonders genau ansehen: die Cookie-Speicherung.
Der Googlebot durchsucht das Web ohne Cookies, akzeptiert diese aber für die Dauer des Ladens einer Seite. Das ist wichtig, denn einige Websites können nur angezeigt werden, wenn Cookies akzeptiert werden, und schlagen fehl, wenn die Annahme von Cookies deaktiviert ist.
Dieses Verhalten imitiert auch der SEO Spider. Standardmäßig akzeptiert er Cookies nur für eine Sitzung. Das bedeutet, dass sie nur für die Dauer des Seitenaufrufs akzeptiert und danach direkt wieder löscht wird.
Du kannst dieses Verhalten zur Cookie-Speicherung ändern und auf dauerhaft umstellen. Dann werden die Cookies über mehrere Seitenaufrufe hinweg gespeichert. Der Begriff dauerhaft ist in diesem Zusammenhang leicht irreführend. Cookies werden beim Start eines neuen Crawls immer zurückgesetzt.
Wenn Du Dich für die Option Nicht speichern entscheidest, werden auch zum Laden der Seite keine Cookies akzeptiert und das kann, wie oben erwähnt, zu Einschränkungen in Funktionalität und Erreichbarkeit führen.
SEO Spider > Einstellungen
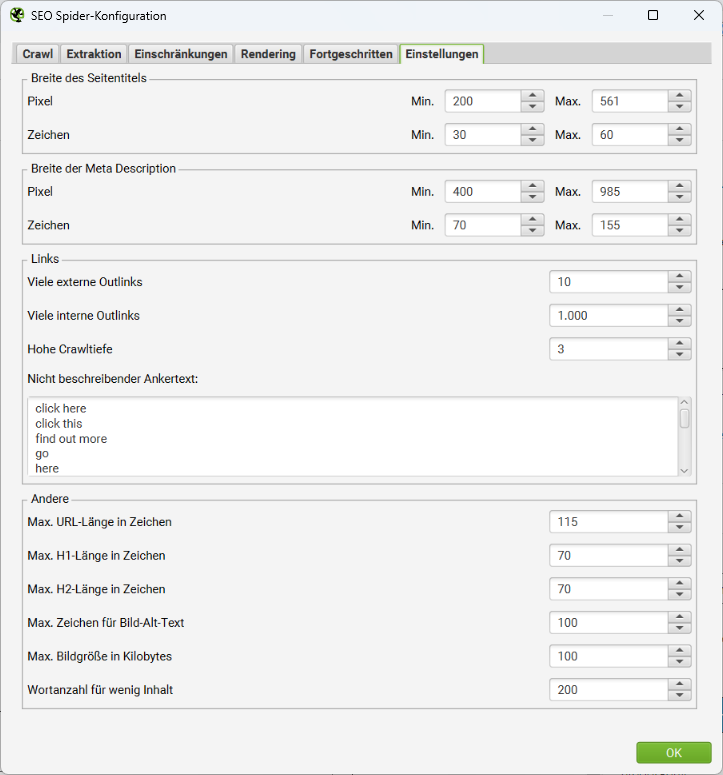
Vielleicht möchtest Du den SEO Spider nutzen, um ein internes Link-Audit zu erstellen? Dann ist für Dich auch von Interesse an welchen Stellen und wie oft Ankertexte gesetzt wurden, die keinen SEO-Mehrwert bieten. Du kannst eine Liste solcher Begriffe wie „weiterlesen“, „mehr“ oder „hier klicken“ im Feld Nicht beschreibender Ankertext pflegen.
Weitere Konfigurationsoptionen
Inhalt
Du kannst hier den eigentlichen Contentbereich einer Website vorgeben, der dann für die Wortzählung, die Analyse von doppeltem Inhalt und die Rechtschreib- und Grammatikprüfung berücksichtigt wird.
Standardmäßig berücksichtigt der SEO Spider Text, der im HTML innerhalb des <body> … </body> enthalten ist und schließt im HTML identifizierbare Navigations- auch Fußzeilen-Elemente aus, um den Contentbereich einer Seite zu definieren.
Aber nicht auf allen Websites werden die semantisch korrekten HTML-Elemente wie <nav> oder <footer> genutzt. Dann ist es sinnvoll, wenn Du selbst Nachjustierungen vornimmst. Hier kannst Du eine Liste von HTML-Elementen, -Klassen oder -IDs einfügen, die für den Contentbereich ein- oder ausgeschlossen werden sollen.
robots.txt
Standardmäßig befolgt der SEO Spider den Regeln einer vorhandenen robots.txt. Er ist dann ebenso wie der Googlebot nicht in der Lage, URLs zu crawlen, die über Anweisungen in der robots.txt ausgeschlossen wurden.
Wenn Du von diesem Verhalten bei Deinem Crawl abweichen möchtest, wählst Du die Option Robots.txt ignorieren. Sie führt dazu, dass der SEO Spider die robots.txt-Datei nicht einmal anguckt. Sämtliche Direktiven bleiben ohne Berücksichtigung.
Die Option Robots.txt ignorieren, aber Status melden bedeutet, dass das Vorhandensein einer robots.txt geprüft und im SEO Spider erfasst wird. Die darin enthaltenen Direktiven werden jedoch ignoriert. Auf diese Weise kannst Du eine Website ohne Einschränkungen crawlen und trotzdem sehen, welche Seiten eigentlich für das Crawling gesperrt sind.
URL-Umschreibung
Das URL-Rewriting des SEO Spiders kann zur Laufzeit eines Crawls Adressen verändern. Hilfreich ist hier vor allem die Option Parameter entfernen.
Mit dieser Funktion kannst Du Parameter in URLs automatisch entfernen lassen. Das ist besonders dann nützlich, wenn interne Links beispielsweise um Session-IDs, Google Analytics-Tracking-Parameter ergänzt wurden.
CDNs
Content-Delivery-Netzwerke (CDNs) sind eine moderne Möglichkeit, die Perfomance einer Website zu erhöhen. Dabei werden bestimmte Teile (oft Grafikdateien oder Skripte) auf externe Servernetze ausgelagert, die weltweit schnelle Zugriffszeiten ermöglichen. Für den SEO Spider ist das grundsätzlich ein Problem: Sämtliche Dateien, die über CDNs ausgeliefert werden, verfügen über eine von der Start-URL abweichende Domäne und sind damit externe Quellen.
In diesem Konfigurationsmenü kannst Du eine Liste von CDNs eingeben, die während des Crawls als intern behandelt werden sollen. Du kannst entweder eine Liste von Domains oder einer Domain + Unterordner angeben.
Zwar stellt der SEO Spider auch zu externen Links Informationen bereit, für interne URLs werden aber mehr Details extrahiert.
Einbeziehen / Ausschließen
Welchen URL-Pfaden soll der SEO Spider folgen? Welche sollen ausgeschlossen werden? Besonders für größere Websites stellen diese Optionen einen guten Weg dar, wie Teilbereiche einer Website gecrawlt werden können.
Eine URL, die auf diesem Weg ausgeschlossen wird, wird nicht gecrawlt. Das bedeutet auch, dass andere URLs, die nicht explizit ausgeschlossen werden, aber nur von einer ausgeschlossenen Seite aus erreicht werden können, ebenfalls nicht gecrawlt werden.
Wichtig: Das Ausschließen von URLs wird nicht auf ursprüngliche URLs, die im Crawl- oder Listenmodus angegeben wurden, sondern lediglich auf neu entdeckte URLs während eines Crawls angewendet.
Geschwindigkeit
Du kannst die Geschwindigkeit des SEO Spider durch die Anzahl gleichzeitiger Threads oder durch die pro Sekunde anzufordernden URLs festlegen.
Die Reduzierung der Geschwindigkeit gelingt am einfachsten durch die Option Max URI/s (maximale Anzahl von URL-Anfragen pro Sekunde). Die Option Max Threads kann dann einfach weggelassen werden.
Die Erhöhung der Threads kann die Geschwindigkeit des SEO Spiders erheblich steigern. Standardmäßig crawlt der SEO Spider mit 5 Threads, um die Server nicht zu überlasten.
Wichtig: Bitte verwende die Threads-Konfiguration mit Bedacht, denn wenn Du die Anzahl der Threads zu hoch einstellst, kann das unter Umständen zu Serverüberlastungen und Systemausfällen führen. Screaming Frog empfiehlt immer, die Crawl-Rate und -Zeit zuerst mit dem Webmaster oder Hosting-Provider abzustimmen, um Problemen vorzubeugen.
SEO: I’ll be responsible & crawl slowly or I could DDoS the site
— Screaming Frog (@screamingfrog) November 28, 2016
Inner SEO: *Increases threads*
SEO: No, wait-
Inner SEO: Light it up pic.twitter.com/YLbrHf00nx
Benutzer-Agent
Mit der User-Agent-Konfiguration gibst Du vor, wie sich der SEO Spider dem Webserver gegenüber identifiziert. Standardmäßig stellt der SEO Spider Anfragen mit seinem eigenen User-Agent: Screaming Frog SEO Spider.
Alternativ kannst Du aber auch voreingestellte User-Agents für Googlebot, Bingbot oder verschiedene Browser wählen oder einen eigenen User-Agent-Eintrag erstellen.
HTTP-Header
Die HTTP-Header-Konfiguration ermöglicht es, während eines Crawls vollständig benutzerdefinierte Header-Anfragen zu stellen: Accept-Language, Cookie, Referer und Headername.
Diese Individualisierung ist beispielsweise dann sinnvoll, wenn Du im HTTP-Header einen Wert für die Accept-Language mitgeben möchtest, um lokal angepasste Inhalte zu crawlen. Du kannst dafür jedes beliebige Sprach- und Regionenpaar angeben.
Wichtig: Der User-Agent wird separat (siehe oben) und nicht unterhalb der Einstellungen für den HTTP-Header konfiguriert.
Benutzerdefiniert
Mit dem SEO Spider kannst Du den Quellcode einer Website frei durchsuchen. Die benutzerdefinierte Suchfunktion überprüft den HTML-Code jeder gecrawlten Seite (vollständig oder ausgewählte Elemente).
Standardmäßig durchläuft die benutzerdefinierte Suche die Rohversion des HTML-Quellcodes einer Website. Hast Du Dich in den Einstellungen jedoch für den JavaScript-Rendering-Modus entschieden, wird hingegen das gerenderte HTML durchsucht. In der Konfiguration der benutzerdefinierten Suche kannst Du bis zu 100 Suchfilter setzen, die die von Dir gewählte Eingabe entweder enthalten oder nicht enthalten.
Benutzeroberfläche
Du kannst hier Veränderungen an den Tabs und Fenstereinstellungen zurücksetzen und zwischen dem hellen oder dunklen Theme für den SEO Spider wählen.
API-Zugang
Du kannst die Funktionalität des SEO Spiders erweitern, wenn Du ihn hier mit weiteren – teilweise kostenpflichtigen – Diensten verknüpfst. In diesem Menü findest Du dazu die entsprechenden API-Einstellungen.
Authentifizierung
Wenn Du Websites crawlen möchtest, auf denen sich Nutzer authentifizieren müssen, würde der SEO Spider normalerweise von diesen geschützten Inhalten ausgeschlossen werden. Damit bei einem Crawl aber auch diese Inhalte erreicht werden können, bietet der Screaming Frog SEO Spider zwei verschiedene Authentifizerungsverfahren an.
Wenn Du eine Website besuchst und im Browser ein Pop-up zur Eingabe von Benutzername und Passwort angezeigt bekommst, handelt es sich um eine solche Basis-Authentifizierung. Für diese Basic Authentication ist keine Einrichtung erforderlich. Sie wird beim Crawlen einer Seite automatisch erkannt. Wie im Browser erscheint dann das Pop-up zur Eingabe. Du kannst dann gültige Daten eintragen und den Crawl fortsetzen.
Wenn der Anmeldebildschirm in der Seite selbst enthalten ist, handelt es sich um eine Webformular-Authentifizierung. Um sich anzumelden, wechselst Du zum Tab Formularbasiert und fügst eine URL der Website hinzu, auf der Du Dich anmelden kannst. Es öffnet sich ein Browserfenster und Du kannst die Anmeldung vornehmen.
Wichtig: Der SEO Spider klickt jeden Link auf einer Seite an. Wenn Du den SEO Spider beispielsweise in Dein Content-Management-System einloggen lässt, könnte er Links zum Abmelden, Erstellen von Beiträgen, Installieren von Plugins oder sogar zum Löschen von Daten folgen und somit unerwünschte Aktionen auslösen.
System
Du kannst festlegen, ob Du die Crawl-Daten im Arbeitsspeicher oder in einer Datenbank auf der Festplatte speichern möchtest. Beide Varianten haben spezifische Vor- und Nachteile.
Standardmäßig verwendet der SEO Spider den Arbeitsspeicher, um Crawl-Daten zu speichern. Der wichtigste Vorteil in diesem RAM-Speichermodus: die Geschwindigkeit.
Da Computer weniger Arbeitsspeicher als Festplattenspeicher haben, eignet sich dieser Modus typischerweise für das Crawlen von Websites mit bis zu 500.000 URLs.
Für größere Crawls gibt es die Möglichkeit, die Crawl-Daten direkt auf dieser Festplatte speichern. Dazu wählst Du hier den Modus Datenbankspeichermodus aus. Geeignet ist dieser Modus bei Verwendung von Festplatten mit SSD-Technologie, weil hier höhere Schreib- und Lesegeschwindigkeiten als bei herkömmlichen Festplatten möglich sind.
Die Vorteile des Datenbankspeichermodus:
- Größere Website-Crawls werden möglich
- Das Öffnen großer Crawls geht schneller
- Crawl-Vergleichs- und Änderungserkennungsfunktionen sind nur in diesem Modus anwendbar